Hacking on Cooper-Hewitt's data release at THATCamp, Or, How to get me to work for free (*)
For THATCamp Prime V, we tried out having a hackathon on a dataset. One suggested dataset was the Cooper-Hewitt data on github. I tried out putting it into an Omeka site and seeing what possibilities were there.
Hacking on the data
There were a couple things that I wanted to do as I pulled the data into Omeka. First, I wanted to map the Cooper-Hewitt data onto Dublin Core as best as I could. Sometimes this was a little tricky, since I wasn't entirely sure of the correct mappings, and was working from just a small sample of what I saw in a tiny handful of real data that I browsed through.
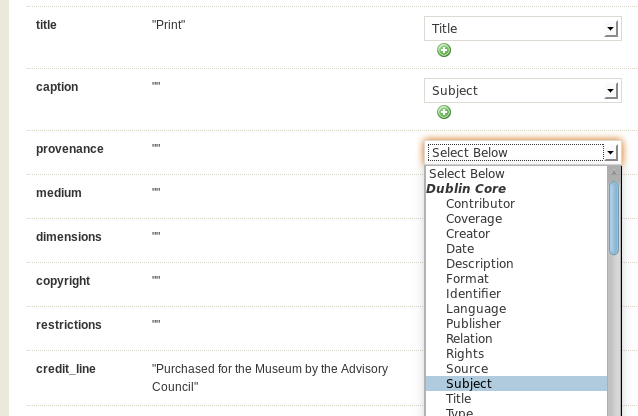 In the first round, I mapped many things onto Dublin Core Subject -- things like 'culture', 'dynasty', and 'period'. I went with that because I figured that, as a broad term, "Subject" would be a nice way to start broad to see lots of material.
In the first round, I mapped many things onto Dublin Core Subject -- things like 'culture', 'dynasty', and 'period'. I went with that because I figured that, as a broad term, "Subject" would be a nice way to start broad to see lots of material.
I also created a "Cooper-Hewitt" item type in Omeka, so that I could recreate those more precise fields. The upshot is that Dublin Core Subject incorporates a lot of different kinds of data found in the CH release, and the item type data maintains the distinctions. That might allow for broad connections via Dublin Core Subject, and more focused connection via the original data.
Since Omeka is mostly about publishing/displaying, I let drop some data, like references to collection ids where I had no data about the collection itself.
Some were a bit more tricky. Where I could map a field in the CH data onto a Dublin Core field, I did that and let it drop from the item type data. On the next import, I will probably not do that. It seemed good at the time in terms of normalization, but once I saw the real outcomes I realized that that was a bad idea. If I can do some normalization into DC and maintain the original data, I should do that with as little data loss as possible. For example, 'provenance' and 'credit_line_repro' were both mapped onto DC Provenance and dropped after that. I should recreate both in the item type data to maintain fidelity to the original, even while I push things together in the DC data.
So I pulled in about a tenth of the data, just to see what it looked like and what ideas it sparked.
And the ideas it sparked -- hoo, boy -- led me into some. . . let's call them complications.
"Ownership" of data
Data came in happily, and I had a site to look at based on the CH data. The 'media_id' field purported to nicely gave a filename for a thumbnail that would connect with their media.csv file. In practice, the real URLs to thumbnails were a little different, but it was easy enough to build the correct URLs ignoring the media.csv data and following the pattern in practice.
So I had a site to clicky-browse around. Turns out, even with only pulling in a fraction of the entire data, I started to see both potentials and problems.
For example, as I clicked around, I found myself wanting to see a screen that listed all of the possible values for a 'culture' or 'period', and get all the items that fit one of those criteria, like "show me all the items from the mid 19th century".
Programaticaly, I'm pretty sure that's easy. But just to make sure, I took a dip into the database to see all the possible values for a field.
That's when I discovered this.
- mid-19th C
- Mid 19th Century
- mid 19th Century
- mid 19th century
- mid-19th century
- Mid-19th century
- Mid-19th Century
Seven different ways in which the concept was expressed.
To be sure, the folks as CH were aware of problems like this. In general, this really isn't a problem. I mean, if I'm looking at just one record, card-catalog style, this gets me the info I need without ambiguity. As a human being reasonable skilled in reading, I'll transparently map each of these mentally onto the same concept without worry.
This is really only a problem when someone like me comes along and wants to work not from understanding an individual record, but from finding ways to group and regroup records with the help of technology.
So, if I wanted (as I do) to produce a page listing all the periods, so people could click to see all the items from that period, that would be inverting the way the data display is designed. That is, these seven different ways to express the same concept, the mid 19th century, work perfectly well if the starting point is a single item and the goal is to give information about it. But, if we want to go the other way, starting with the concept of 'mid 19th century' and see what's relevant, this completely fails.
That's when the magic of Cooper-Hewitt releasing the data on GitHub, under a CC-0 Public Domain Dedication really hit me.
If the data had been available via an API, that would have put a huge burden on my site. I could have grabbed the data for the 'period', but to make it useful in my recontextualization of the data, I would have had to grab ALL the data, then normalize it, then display it. And, if I didn't have the rights to do what I needed, I would have had to do that ON EVERY PAGE DISPLAY. That is, without the licensed rights to manipulate and keep the data as I needed, the site would have churned to a halt.

Instead, I could operate on the data as I needed. Because in a sense I own it. It's in the public domain, and I have a site that wants to work with it. That means that the data really matters to me, because it is part of my site. So I want to make it better for my own purposes. But, also, since it is in the public domain, any improvements I make for my own purpose can and should go back into the public domain. Hopefully, that will help others. It's a wonderful, beautiful, feedback loop, no?
As a fork of CC-0 content from github, it sets off a wonderful network of ownership of data, where each node in the network can participate in the happy feedback.
Google Refining for free
With an idea for a site and how it could display the data, I needed to start making the data work well with my ideas. Basically, I just wanted, for example, links to items related to the nineteenth century to show up together alphabetically. Clearly, starting with "Mid" would produce some problems when we talk about more than one century. "Mid 16th century" would show up close to "Mid 20th century". Not the desired outcome.
This turned out to be a great chance to use Google Refine for real. I'd played with it on fake data, but now I had data that I cared about because it would go into a site with my name on it -- and Cooper-Hewitt's.
For example, this
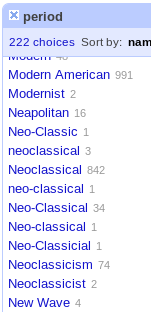 became
became 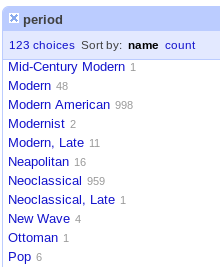 very quickly and easily. Nice!
very quickly and easily. Nice!
After a few hours cleaning up a LOT -- and I mean a LOT of data this way -- I suddenly asked myself why I was doing all this work for Cooper-Hewitt for free.
The point is that I wasn't, or at least not exclusively. I was doing the work for me, too, because I was taking some ownership of the data as it related to the representation of it that I wanted to produce. So, they'll get some cleaned up data if they accept the pull request, and I'll get some nicer data to produce a nicer display if I follow through and keep building the site.
So, why did I spend some hours (and will spend more) cleaning up data and contributing it back?
- The data is in the public domain, so I own it, and so do all of you, and we can do useful things with it.
- I came up with a small project of my own to do something possibly useful with it. The fact that the project was all mine in the implementation gave me even greater sense of ownership of the data -- and hence responsibility for data along with my responsibility for the project.
So What?
The folks at Cooper-Hewitt knew that there were some problems with the data, and probably were hoping that by releasing it this way they would get some folks to improve it in a crowdsourcing kind of way. Here's an idea on how to more strongly prompt that into action.
In addition to releasing the data, suggest some project ideas for people to pick up, even while pointing to possible data clean-up that might be needed for the project. For example:
- Take the data and put it into ViewShare (you might also want to map some fields into more standard schema)
- Take the data and put it into Omeka (you might need to normalize some of the field values)
- Take the data and RDFize it (you might want to explore the possible schema available for the various fields, and mint Cool URIs for each record)
I'm sure there are other possible projects to suggest. I'm also pretty sure that various people -- and maybe even some university courses -- would welcome the suggestions for projects that could let them build something while engaging in the shared improvement of data that we all own.
(*) Roy Rosenzweig Center for History and New Media is disqualified from this offer
"Any medium powerful enough to extend man's reach is powerful enough to topple his world. To get the medium's magic to work for one's aims rather than against them is to attain literacy."
-- Alan Kay, "Computer Software", Scientific American, September 1984
Add comment